How I would have designed the JKJAVMY AstraZeneca appointment database
The third round of registration in Malaysia for the AstraZeneca vaccine closed leaving many (including myself and loved ones) in frustration because the system was (again) unable to handle the load — “frustration” a bit understated here given how Malaysia is now leading the world in Covid cases per million.
To cope, I can only try to diagnose where it went wrong.
Designing for traffic spikes is a challenge
The litmus test for application design is dealing with traffic spikes— especially for transactional use-cases. A transactional use-case (like the AZ appointments) is one where writing and reading data is dependent on other criteria (slot availability), and writes need to fail if the slots are not available.
Non-transactional use-cases, like serving a news article or posting a comment, are trivial because you can cache reads and delay writes without doing additional checks.
A litany of failures
There were (many) other failings in the design of the https://www.vaksincovid.gov.my/ appointment systems, among them:
- No visual feedback to the user when appointment slots fail to load — the user has no idea what to do next.

- Loading appointment slots and submitting the form caused several errors, all with no visual feedback and no indicator on what to do next. Some of the errors returned were “500 Service Unavailable/Timeout” (seen above). Other times, the error was “429 Too Many Requests”, which means that the user should NOT retry what they are doing, or risk being blocked for a longer time — this ommission is especially fatal because of the lack of visual feedback.
It’s all about the database
However, experience and intuition tells me the overarching failure was in the design of the database.

In modern cloud design, the application layers can scale infinitely with little effort or expertise. However this is not true of the data layer. Unfortunately many software engineers do not regularly deal with “internet-scale” applications. Without specific preparation and experience, they will fall short when called to do so.
The most common shortcoming when designing a high-traffic transaction system is relying on a single, monolithic database. The only way to improve performance in the overall system is to have a database with the most CPU/RAM available. The problems with these are:
- Most monolithic databases cannot scale automatically — my intuition is this is why the system needed to be down at 10am-12noon.
- Once you have allocated the largest database size available (about 100 CPU units on Amazon Web Services), you are out of options. You can only watch helplessly as all your tables and connections lock, and your users undergo a roulette of whether both their request to get the appointment slots AND submitting their form both go through.
Partitioning is the answer
The good (or bad, depending on how accountable you hold JKJAVMY) news is that architecting internet-scale databases has been a solved problem for a while now. The answer is simply data partitioning.

Breaking up your data into partitions is hard if you don’t know how the data needs to be accessed — but this was not the case here.

Even if you are non-technical, you can see that appointment slots have been allocated per day, per PPV (Pusat Pemberian Vaksin, or Vaccine Dispensation Center) location, per state. The availability of slots in June 22 in UM has no bearing on the availability of a slot in July 22 in Penang.
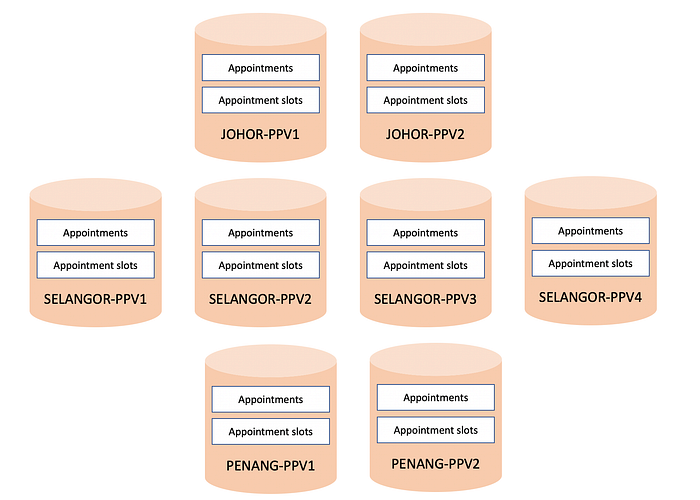
A first pass would be to partition the slots by PPV as shown here. This distributes requests more evenly, and isolates traffic load.
There is some development expertise involved in this in how to manage transactions per partition — but is well documented. Amazon DynamoDB for example supports this, and is a prominent design pattern:
DynamoDB scales up to tens of thousands of writes per second when designed correctly — that’s a default quota, which could probably raised if you had say, a RM 70mil budget.
Given that the high load had happened in the previous two rounds, I would have gone even deeper into the partitioning and actually partitioned the data per PPV, per day.
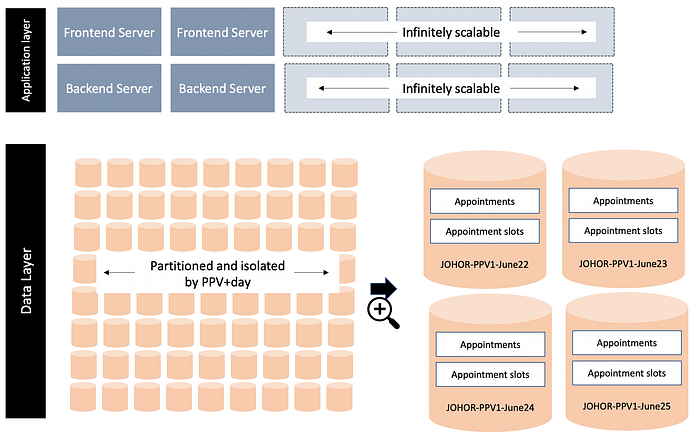
This design has a benefit in that even if some PPV/date combinations had been overloaded, the data isolation would have meant other PPV/date combinations would have been available.
Please do better
There are definitely other things that could have been done— a queue system, a waiting area, etc — or not to have a booking system at all. I hope JKJAVMY improves the process as lives are at stake.
